{
{
"dialogue 1": {
"characters": [
"sparrow",
"lion",
"eagle"
],
"scene": [
"library"
],
"turn 1": {
"caption": "In the silent library, a tiny sparrow was fluttering near a shelf.",
"objects": [
[
"a tiny sparrow",
[
115.5,
170.5,
89,
59
],
1
],
[
"a library shelf",
[
215.5,
165.5,
171,
171
],
2
]
],
"background": "A silent library",
"negative": "None"
},
"turn 2": {
"caption": "An attentive lion in one corner was carefully observing the bird and holding its breath.",
"objects": [
[
"an attentive lion",
[
300.5,
221.0,
162,
180
],
3
],
[
"a tiny sparrow",
[
40.5,
101.0,
89,
59
],
1
]
],
"background": "A silent library",
"negative": "None"
},
"turn 3": {
"caption": "Above them, a vigilant eagle watched the suspenseful scene unfold from the library ceiling.",
"objects": [
[
"a vigilant eagle",
[
345.5,
41.0,
119,
72
],
4
],
[
"an observing lion",
[
295.5,
281.0,
162,
180
],
3
],
[
"a sparrow",
[
45.5,
171.0,
89,
59
],
1
]
],
"background": "A silent library",
"negative": "None"
},
"turn 4": {
"caption": "The scenario ended peacefully as the eagle, the lion, and the sparrow all resumed their own activities in the vast library.",
"objects": [
[
"an occupying eagle",
[
335.5,
41.0,
119,
72
],
4
],
[
"a peaceful lion",
[
285.5,
281.0,
162,
180
],
3
],
[
"a sparrow",
[
55.5,
181.0,
89,
59
],
1
]
],
"background": "A vast library",
"negative": "None"
}
}
}
}
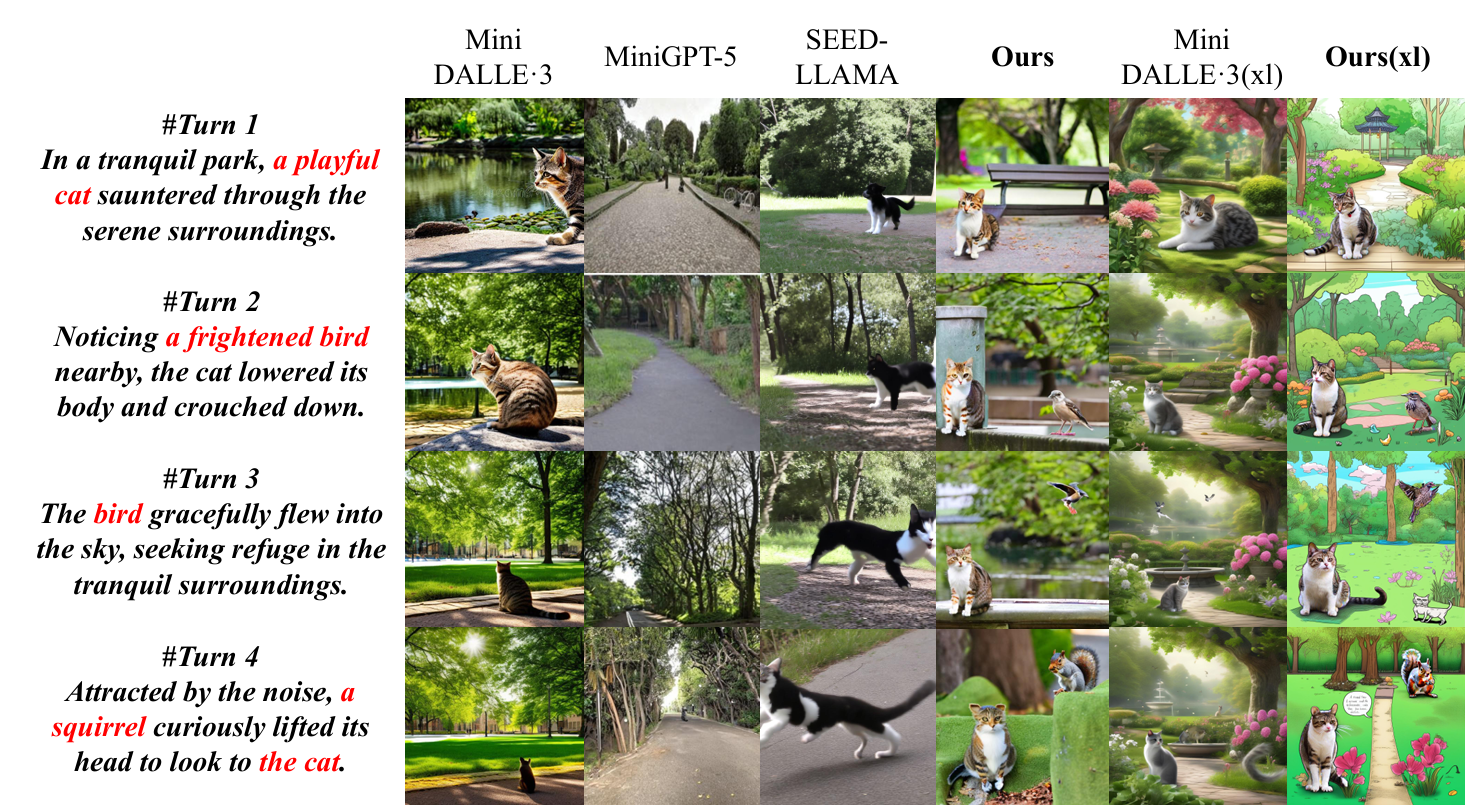
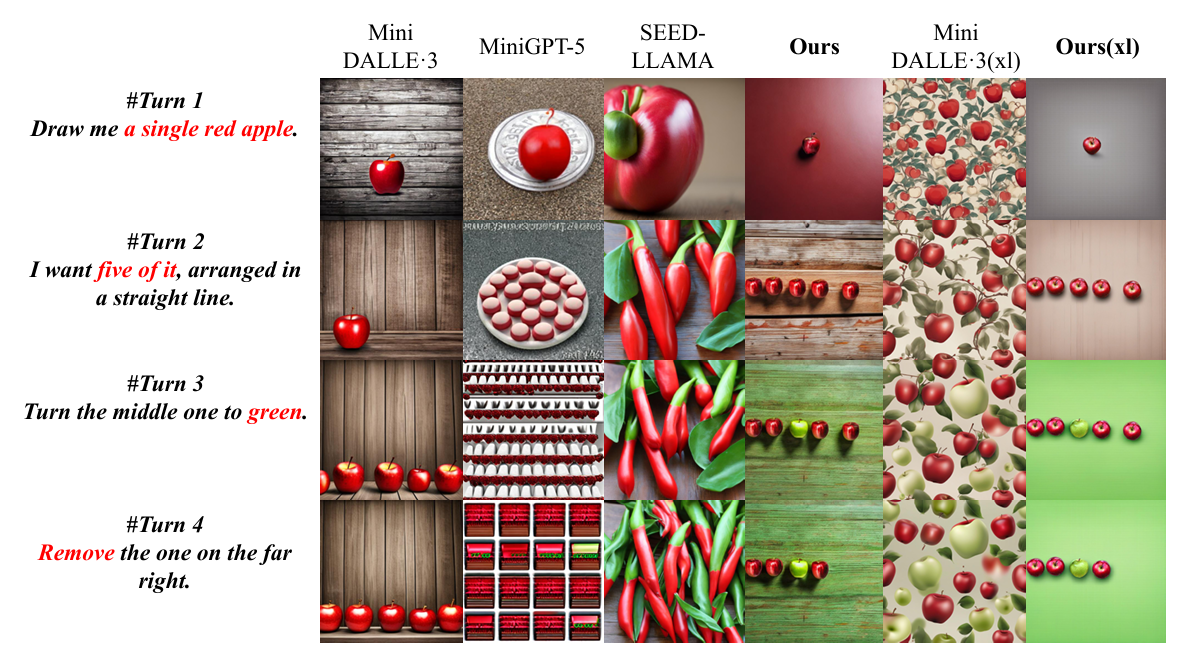
we propose a Consistent Multi-turn Image Generation Benchmark: CMIGBench. This benchmark focuses on two common types found in multi-turn image generation: story generation and multi-turn editing, comprising 8000 multi-turn scripted dialogues (4000 for each task) with each consisting of 4 turns of natural language instructions. This allows us to evaluate the semantic consistency and contextual consistency of different models in multi-turn image generation in a zero-shot manner.